Математические методы
Математические методы в медицине — совокупность методов количественного изучения и анализа состояния и (или) поведения объектов и систем, относящихся к медицине и здравоохранению. В биологии, медицине и здравоохранении в круг явлений, изучаемых с помощью М.м., входят процессы, происходящие на уровне целостного организма, его систем, органов и тканей (в норме и при патологии); заболевания и способы их лечения; приборы и системы медицинской техники; популяционные и организационные аспекты поведения сложных систем в здравоохранении; биологические процессы, происходящие на молекулярном уровне.
Степень математизации научных дисциплин служит объективной характеристикой глубины знаний об изучаемом предмете. Так, многие явления физики, химии, техники описываются М.м. достаточно полно. В результате эти науки достигли высокой степени теоретических обобщений. В биологических науках М.м. пока еще играют подчиненную роль из-за сложности объектов, процессов и явлений, вариабельности их характеристики, наличия индивидуальных особенностей. Систематические попытки использовать М.м. в биомедицинских направлениях начались в 80-х гг. 19 в. Общая идея корреляции, выдвинутая английским психологом и антропологом Гальтоном (F. Galton) и усовершенствованная английским биологом и математиком Пирсоном (К. Pearson), возникла как результат попыток обработки биомедицинских данных. Точно так же из попыток решить биологические проблемы родились известные методы прикладной статистики. До настоящего времени методы математической статистики являются ведущими М.м. для биомедицинских наук. Начиная с 40-х гг. 20 в. математические методы проникают в медицину и биологию через кибернетику и информатику. Наиболее развиты М.м. в биофизике, биохимии, генетике, физиологии, медицинском приборостроении, создании биотехнических систем. Благодаря М.м. значительно расширилась область познания основ жизнедеятельности и появились новые высокоэффективные методы диагностики и лечения; М. м. лежат в основе разработок систем жизнеобеспечения, используются в медицинской технике.
Все большую роль во внедрении М.м. в медицину играют ЭВМ (см. Электронная вычислительная машина). В частности, применение методов математической статистики облегчается тем, что стандартные пакеты прикладных программ для ЭВМ обеспечивают выполнение основных операций по статистической обработке данных. М.м. смыкаются с методами кибернетики и информатики, что позволяет получать более точные выводы и рекомендации, внедрять новые средства и методы лечения и диагностики.
Математические методы применяют для описания биомедицинских процессов (прежде всего нормального и патологического функционирования организма и его систем, диагностики и лечения). Описание проводят в двух основных направлениях. Для обработки биомедицинских данных используют различные методы математической статистики, выбор одного из которых в каждом конкретном случае основывается на характере распределения анализируемых данных. Эти методы предназначены для выявления закономерностей, свойственных биомедицинским объектам, поиска сходства и различий между отдельными группами объектов, оценки влияния на них разнообразных внешних факторов и т.п. На основе определенной гипотезы о типе распределения изучаемых данных в серии наблюдений и использования соответствующего математического аппарата с той или иной достоверностью устанавливаются свойства биомедицинских объектов, делаются практические выводы, даются рекомендации. Описания свойств объектов, получаемые с помощью методов математической статистики, называют иногда моделями данных. Модели данных не содержат какой-либо информации или гипотез о внутренней структуре реального объекта и опираются только на результаты инструментальных измерений.
Другое направление связано с моделями систем и основывается на математическом описании объектов и явлений, содержательно использующих сведения о структуре изучаемых систем, механизмах взаимодействия их отдельных элементов. Разработка и практическое использование математических моделей систем (математическое моделирование) составляют перспективное направление применения М.м. в биологии и медицине.
Статистические методы обработки стали привычным и широко распространенным аппаратом для работников медицины и здравоохранения, например диагностические таблицы, пакеты прикладных программ для статистической обработки данных на ЭВМ (см. Программирование). Однако использование этой группы М.м. вызвало ряд проблем принципиального характера, связанных с выбором адекватного задаче метода статистической обработки и содержательно обоснованного его применения. Эти факторы послужили причиной роста требований к качеству статистической обработки экспериментальных и клинических данных, в т.ч. для публикации результатов исследований в научных журналах. Ранее считалось достаточной обработка данных простейшими статистическими методами и простыми формами корреляционного и регрессионного анализа. Это, как показал опыт, далеко не всегда позволяет выявить сущность исследуемых явлений и, более того, не дает гарантий в отношении надежности результатов. В СССР сложившееся положение частично вызвано недостаточным количеством ЭВМ, а в основном — недостаточным уровнем подготовки работников медицины и здравоохранения в области прикладной статистики.
Существует несколько основных понятий, необходимых для эффективного использования методов современной многомерной статистики.
Статистическая совокупность — понятие, лежащее в основе всех статистических методов. Объекты, с которыми имеют дело в медицине, обладают большой вариабельностью — их характеристики меняются во времени и пространстве в зависимости от многих факторов, а также существенно отличаются друг от друга, Характеристики таких объектов обычно представляют в виде матрицы наблюдений, где столбцы соответствуют различным признакам, а строки — либо разным объектам, либо последовательным во времени наблюдениям за одним и тем же объектом.
Из-за вариабельности измеряемых признаков приходится считать их значения случайными величинами и пользоваться вероятностными (стохастическими) постановками задач: матрица наблюдений является выборкой, или выборочной совокупностью случайных величин из некоторой генеральной совокупности. Сама генеральная совокупность обычно трактуется как множество всех объектов определенного типа или как совокупность всех возможных реализаций какого-либо явления. Основными задачами статистического исследования являются выявление и анализ закономерностей, присущих объектам в выборке, с целью установления возможности и достоверности перенесения сделанных выводов на генеральную совокупность.
Признаки, характеризующие объекты в медицине и здравоохранении, подразделяются на количественные, порядковые и качественные. Для количественных признаков можно указать точную характеристику — число (например, вес, рост, величина АД, данные анализов), Для порядковых признаков (ранговых, если каждой градации ставится в соответствие число — ранг) точная характеристика невозможна, но можно указать степень выраженности соответствующего свойства (хрипы в легких — единичные, множественные; интенсивность кашля — слабая, средняя, сильная, очень сильная). Качественные признаки не поддаются упорядочиванию или ранжированию (цвет глаз — голубой, серый, карий).
Обычно объекты в биологии и медицине описываются множеством признаков одновременно. Набор учитываемых при исследовании признаков называется пространством признаков. Значения всех этих признаков для данного объекта однозначно определяют его положение как точку в пространстве признаков. Если признаки рассматриваются как случайные величины, то точка, описывающая состояние объекта, занимает в пространстве признаков случайное положение.
Закон распределения случайной величины — это функция, определяющая вероятность того, что какой-либо признак примет заданное значение (если он дискретен) или попадает в заданный интервал значений (если он непрерывен). При большом числе выборочных данных, значения которых варьируют незначительно, закон распределения может быть аппроксимирован гистограммой. Для построения гистограммы интервал значений признака разбивается на равные участки, для которых подсчитывается частота попадания случайной величины. При бесконечном увеличении числа наблюдений и участков частота стремится к вероятности, а вид гистограммы приближается к кривой, выражающей функцию плотности (или плотности вероятности) случайной величины.
Законы распределения могут быть одномерными и многомерными. В последнем случае закон описывает вероятность появления сочетанных значений признаков или попадания их в некоторую область пространства признаков. В прикладной статистике особую роль играют несколько наиболее часто используемых законов распределения. Наиболее разработана гипотеза о нормальном распределении (закон Гаусса), функция плотности вероятности f (x) для которого имеет вид:
![]()
где М — математическое ожидание,
s — среднеквадратическое (стандартное) отклонение,
е — основание натуральных логарифмов (e = 2.718...).
Параметры закона Гаусса М и s приближенно оцениваются по любой выборке из генеральной совокупности:
![]()
![]()
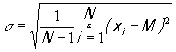 ,
,
где N — объем выборки, х — значение исследуемого количественного признака для 1-го измерения.
Величина о, возведенная в квадрат, называется дисперсией: D = s2 Дисперсия характеризует разброс (вариабельность) случайной величины около среднего значения. При нормальном распределении случайной величины ее наблюдаемые значения с большой вероятностью (равной 0,9972) отклоняются от М в ту или другую сторону не более чем на 3s (правило трех сигм).
Оценка математического ожидания М по выборке (называемая выборочным средним) тоже является случайной величиной. Она описывается так называемым распределением Стьюдента. Это распределение зависит от числа наблюдений (числа степеней свободы) и приводится в справочниках по прикладной статистике. Критерий Стьюдента (t-критерий) используется для оценки и сравнения средних значений нормально распределенных случайных величин. Имеется обобщение закона и критерия Стьюдента на многомерный случай.
Выборочная дисперсия также является случайной величиной, распределение которой получило название распределения c2 (хи-квадрат) Пирсона (по имени одного из основоположников биометрии). Таблицы значений c2 включены во все пособия по статистике. На основании распределения c2 строятся доверительные интервалы случайных величин.
Для сравнения выборочных дисперсий двух серий наблюдений используют распределение Фишера, которое зависит от числа степеней свободы обеих выборок и также представлено в табличной форме. Критерий Фишера (F-критерий) применяется для сравнения выборочных дисперсий и формирования оценок в регрессионном, дисперсионном и дискриминантном анализе.
Перечисленные типы распределений относятся к непрерывным случайным величинам. Для дискретных случайных величин используется распределение Пуассона (закон редких явлений):
![]()
где М — значение математического ожидания и равное ему значение дисперсии, Pk — вероятность того, что случайная величина принимает значение, равное k (здесь k — любое целое число).
Для таких же величин применяется закон распределения числа взаимоисключающих событий при конечном числе испытаний (биномиальное распределение). Эти распределения употребляются для описания случайных значений параметров в медицинской диагностике, при анализе популяционных процессов и т.п.
Статистическое оценивание применяют в медицинских исследованиях, когда получаемых данных недостаточно для установления вида функции распределения случайных величин. В этом случае предполагают, что реализуется один из законов распределения, а матрицу наблюдений используют для оценки параметров этого закона.
Статистические оценки могут быть точечными или интервальными. В первом случае оценка дается в виде чисел (как правило, это среднее значение и дисперсия). Во втором случае определяется интервал, в котором исследуемая случайная величина находится с заданной вероятностью. Получаемые оценки должны относиться к генеральной совокупности. Интервальная оценка генерального среднего (математического ожидания) производится на основе распределения Стьюдента (при числе наблюдений не более 50—60) или на основе гипотезы о нормальном распределении (при большем числе наблюдений). Для оценки генеральной дисперсии применяется распределение c2. Интервал, в котором с заданной вероятностью находится генеральный параметр, называется доверительным интервалом, сама такая вероятность — доверительной вероятностью. В медицинских исследованиях используют три порога доверительной вероятности b: 0,95; 0,99; 0,999. Чем точнее требуется результат, тем большим порогом задается исследователь и тем шире (при прочих равных условиях) получается доверительный интервал. В статистике наряду с понятием доверительной вероятности употребляется термин «уровень значимости». Соответственно применяются три уровня значимости 0,05; 0,01 и 0,001.
Проверка статистических гипотез используется чаще всего для определения принадлежности двух имеющихся выборок к одной и той же генеральной совокупности. Подобные задачи возникают, например, при анализе заболеваемости, эффективности лекарственных препаратов и т.п.
Гипотеза о том, что обе выборки не различаются, т.е. принадлежат к одной генеральной совокупности, называется иногда нуль-гипотезой. Эта гипотеза принимается, если ее значимость, получаемая на основании статистических критериев, превышает допустимый порог (р > 0,95). Однако при р < 0,95 отвергнуть эту гипотезу нельзя: ответ остается неопределенным, и для получения окончательного вывода требуются дополнительные данные. Гипотеза отвергается в том случае, если ее значимость (вероятность правильности) становится меньше заданного стандартного порога.
При проверке статистических гипотез используются параметрические и непараметрические критерии. В первом случае производится сравнение параметров двух выборочных распределений (средних и дисперсий) и делается заключение о равенстве или различии этих параметров в генеральных совокупностях. Гипотеза о равенстве средних значений проверяется по критерию Стьюдента, равенство дисперсий — по критерию Фишера. Описание соответствующих процедур можно найти в любом пособии по математической статистике.
В последние годы большую популярность приобрели непараметрические критерии (Уилкоксона, Колмогорова — Смирнова и др.). Их достоинством является то, что они не содержат ограничений, вытекающих из гипотез о типе распределения случайных величин, а опираются на единый принцип — непрерывности распределений.
Эти критерии применимы и для анализа порядковых данных. Однако по сравнению с параметрическими методами они менее чувствительны к различиям в выборках. Чаще всего непараметрические критерии используются для сравнения эмпирического распределения с теоретическим, в частности при проверке имеющейся статистической совокупности на принадлежность к типу нормальных распределений.
Дисперсионный анализ — статистический метод, применяемый для выявления влияния отдельных факторов (количественных, порядковых или качественных) на изучаемый признак и оценку степени этого влияния. Если изучается действие количественного фактора, то предварительно производится его разбивка на градации. Для каждой градации подсчитывается среднее значение изучаемого признака, затем дисперсия среднего по градациям фактора относительно общего среднего и, наконец, общая дисперсия изучаемого показателя (независимо от значения фактора).
В теории дисперсионного анализа показано, что общая дисперсия D равна дисперсии средних по градациям фактора DF (доля дисперсии за счет действия исследуемого фактора — объясненная дисперсия) плюс остаточная дисперсия за счет действия случайных факторов (DS): D = DF + DS. Чем больше эта величина, тем сильнее влияние фактора на изучаемый признак.
Для количественной оценки степени влияния вычисляют показатель F по формуле:
![]() ,
,
где L — число градаций фактора, N — объем статистической совокупности.
Показатель влияния F затем сравнивается со стандартным значением Fst в таблице Фишера (для выбранного уровня значимости при соответствующем числе степеней свободы). Если F > Fst то факт влияния считается достоверно доказанным.
Описанная схема называется однофакторным дисперсионным анализом.
Анализ зависимости между признаками. Для оценки степени взаимозависимости двух количественных признаков чаще всего используют коэффициент ковариации или его нормированное значение — коэффициент корреляции:
![]()
где xi и yi — значения первого и второго признаков в 1-м наблюдении, sx и sy — стандартные отклонения первого и второго признаков; N — объем выборки, Х и Y — математические ожидания х и у.

Ваш комментарий